
Prompt Engineering Patterns: Complete guide 2026
This post covers 15 types of prompt engineering patterns.

The single most common mistake in AI development isn’t choosing the wrong model. It’s using the wrong prompting pattern for the task.
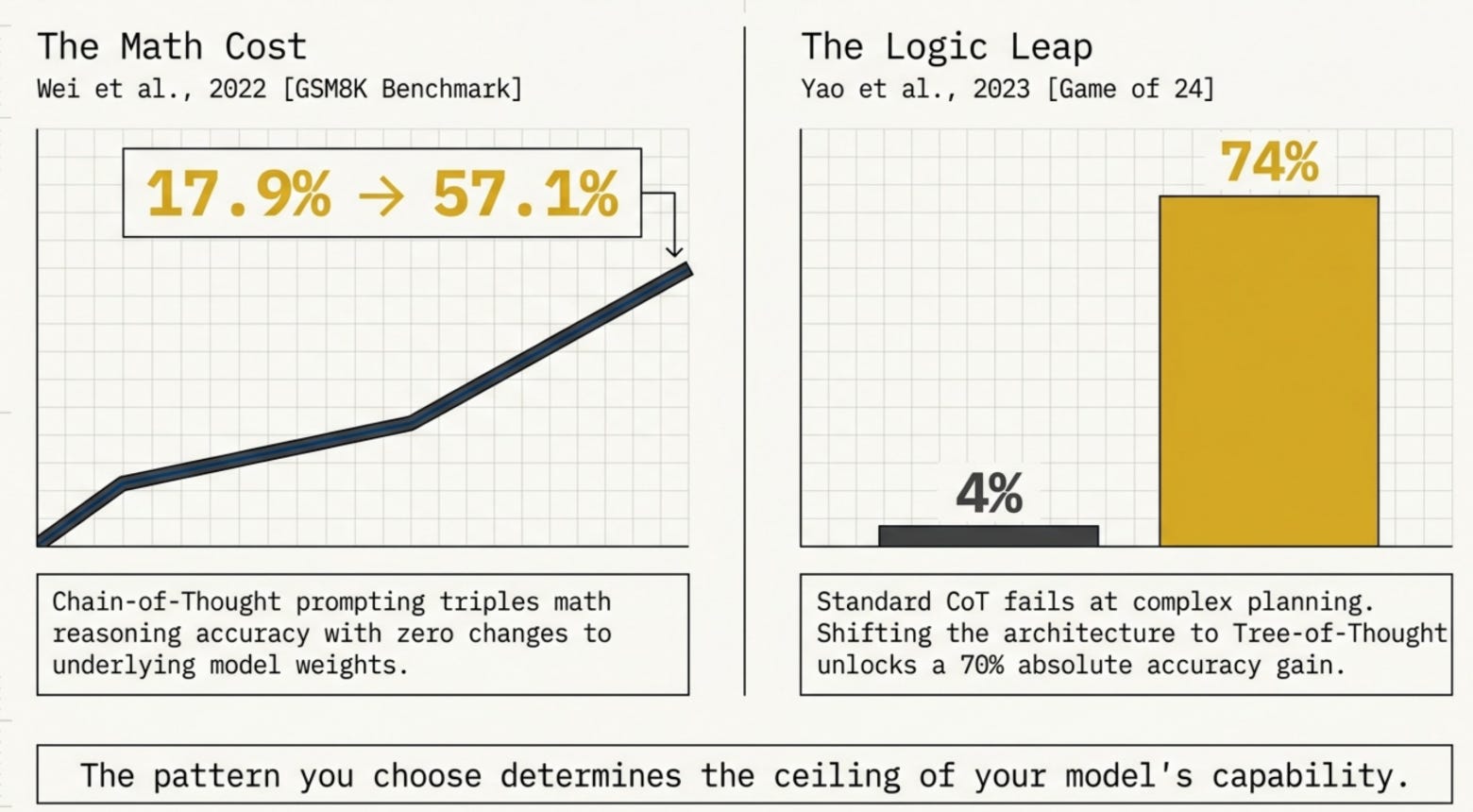
Chain-of-Thought prompting alone pushed GPT accuracy on grade-school math from 17.9% to 57.1% -- a 3x improvement with zero changes to the model (Wei et al., 2022). Tree-of-Thought took GPT-4 from 4% to 74% on the Game of 24 reasoning benchmark (Yao et al., NeurIPS 2023). The pattern you choose matters at least as much as the model you’re prompting.
This guide maps all 15 major prompt engineering patterns, their research foundations, and exactly when to use each one.
Key Takeaways
Chain-of-Thought prompting improved math reasoning accuracy by 3x on GSM8K with no model changes (Wei et al., 2022)
Tree-of-Thought solved 74% of Game of 24 tasks vs. 4% with standard CoT (Yao et al., NeurIPS 2023)
Self-Consistency added +17.9% on GSM8K by running CoT multiple times and taking the majority vote (Wang et al., 2022)
ReAct (Reason + Act) is the architectural foundation of most AI agents in production today
What Is Prompt Engineering and Why Does the Pattern Matter?
Prompt engineering is the practice of structuring inputs to a language model to reliably produce better outputs. It’s not just wording -- it’s architecture. The pattern you choose changes how the model processes the problem, whether it reasons step-by-step, explores multiple paths, retrieves external knowledge, or delegates computation to code.
Think of it as choosing the right tool for the job. A hammer and a screwdriver are both useful; using the wrong one is simply a waste. The same applies here: Zero-Shot works perfectly for simple classification. Using Tree-of-Thought for the same task wastes money and adds latency.
Layer 1 -- The Foundation: Zero-Shot and Few-Shot
1. Zero-Shot Prompting
Zero-Shot gives the model a task with no examples at all. The model relies purely on patterns from pretraining.
Classify the sentiment: "The product broke on day one."
It’s fast, cheap, and surprisingly effective for well-understood tasks. Zero-shot is the correct default before anything else -- add complexity only when it fails.
Best for: Classification, summarization, translation, simple Q&A. Avoid when: The task requires a specific format or domain-specific behavior the model hasn’t seen.
2. Few-Shot Prompting
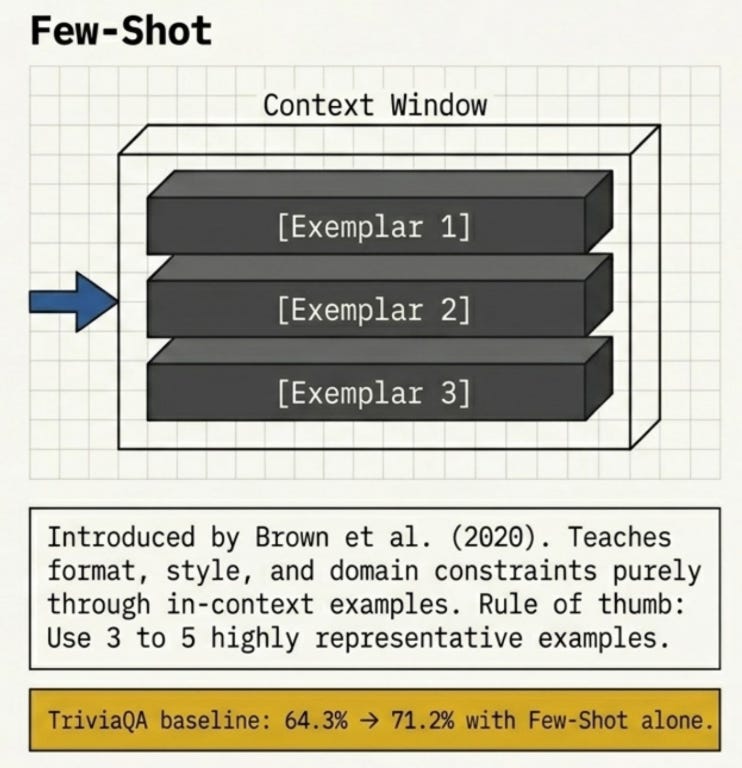
Few-Shot (introduced at scale with GPT-3, Brown et al., 2020) provides 2-5 examples before the actual task. The model learns the pattern from context rather than training.
Positive → Happy
Negative → Sad
Neutral → Calm
Now classify: "The food was edible, nothing more."
On TriviaQA, GPT-3 jumped from 64.3% (zero-shot) to 71.2% (few-shot) purely through in-context examples (Brown et al., 2020). No fine-tuning, no retraining.
Best for: Teaching format, style, domain-specific behavior, structured output. Key rule: Use 3-5 examples. Too few doesn’t establish the pattern; too many wastes context.
Worth noting: Few-shot works best when your examples represent the full range of expected inputs -- including edge cases. A common mistake is using only “easy” examples, which trains the model on an unrepresentative distribution.
Layer 2 -- Reasoning Patterns: CoT, ToT, Self-Consistency
3. Chain-of-Thought (CoT) Prompting
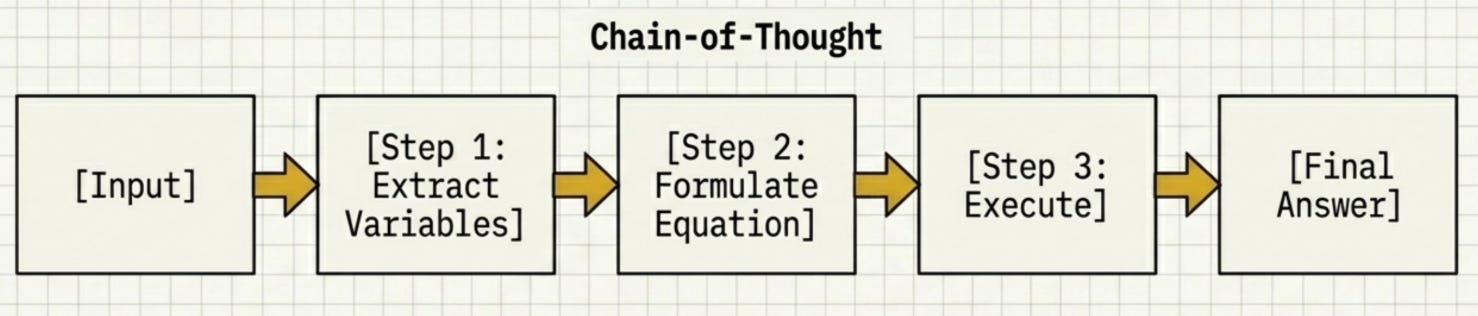
Chain-of-Thought asks the model to reason through intermediate steps before giving a final answer (Wei et al., 2022). The phrase “Let’s think step by step” -- introduced by Kojima et al. (2022) -- is enough to trigger this in zero-shot mode.
Q: Roger has 5 tennis balls. He buys 2 more cans of 3 balls each. How many does he have?
A: Roger starts with 5. He buys 2 cans × 3 balls = 6 balls. 5 + 6 = 11 balls.
The results are striking: GSM8K accuracy went from 17.9% (standard prompting) to 57.1% with CoT exemplars -- a 3x gain (Wei et al., 2022). CoT is an emergent property of scale and works best on models above ~100B parameters.
Best for: Multi-step math, logical reasoning, planning, troubleshooting. Avoid when: The task is simple -- CoT adds tokens and latency for no benefit on easy tasks.
4. Tree-of-Thought (ToT) Prompting
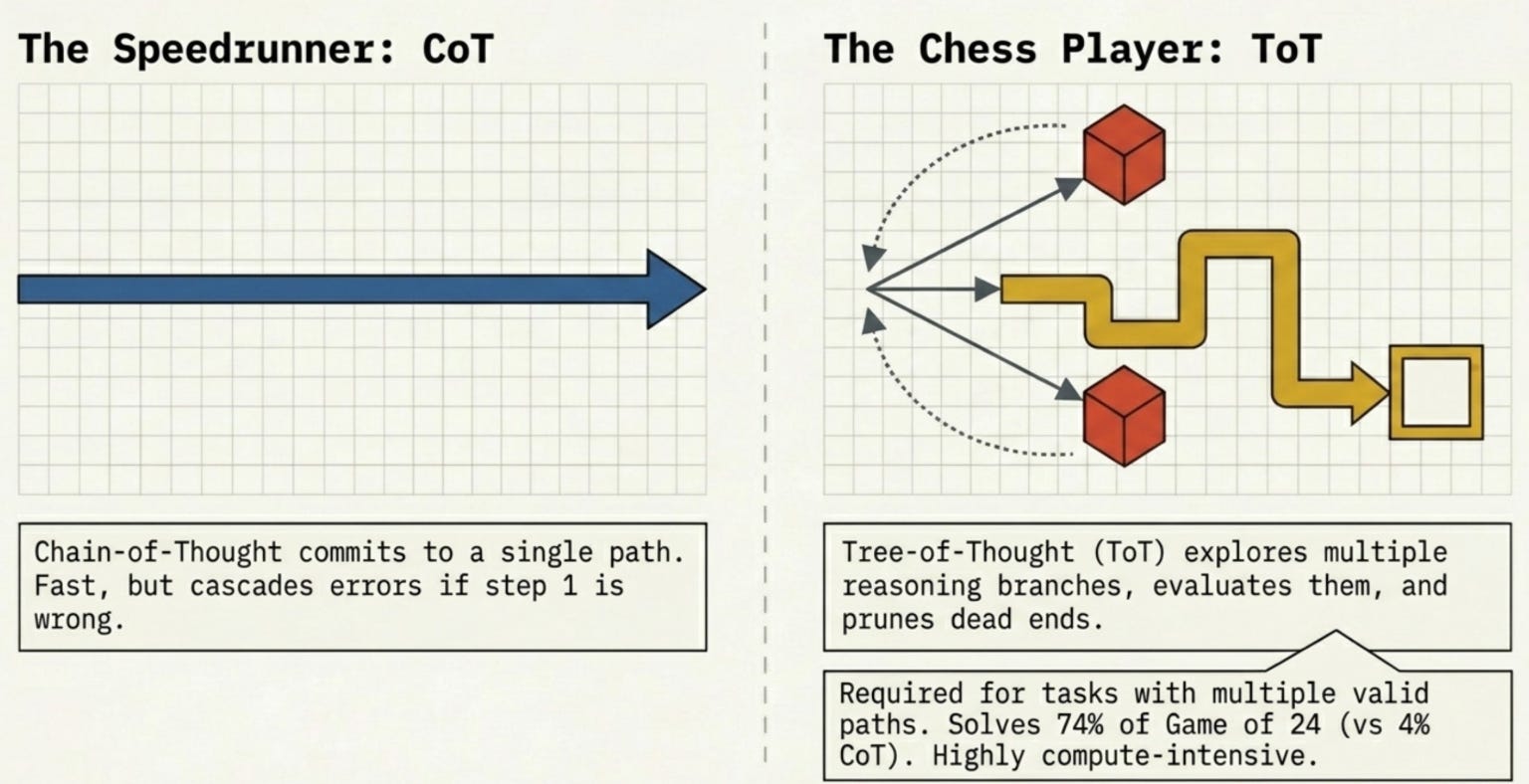
Tree-of-Thought extends CoT by exploring multiple reasoning branches simultaneously and pruning dead ends (Yao et al., NeurIPS 2023). Where CoT commits to a single reasoning path, ToT backtracks and evaluates alternatives.
Think of it as the difference between a speedrunner and a chess player. CoT runs forward; ToT looks several moves ahead.
On Game of 24 (reach 24 using four numbers and basic arithmetic), GPT-4 with standard CoT solved just 4% of tasks. With Tree-of-Thought: 74% (Yao et al., 2023).
Best for: Complex problem-solving, creative tasks with many valid approaches, planning with constraints. Avoid when: Cost is a concern -- ToT is significantly more expensive than CoT.
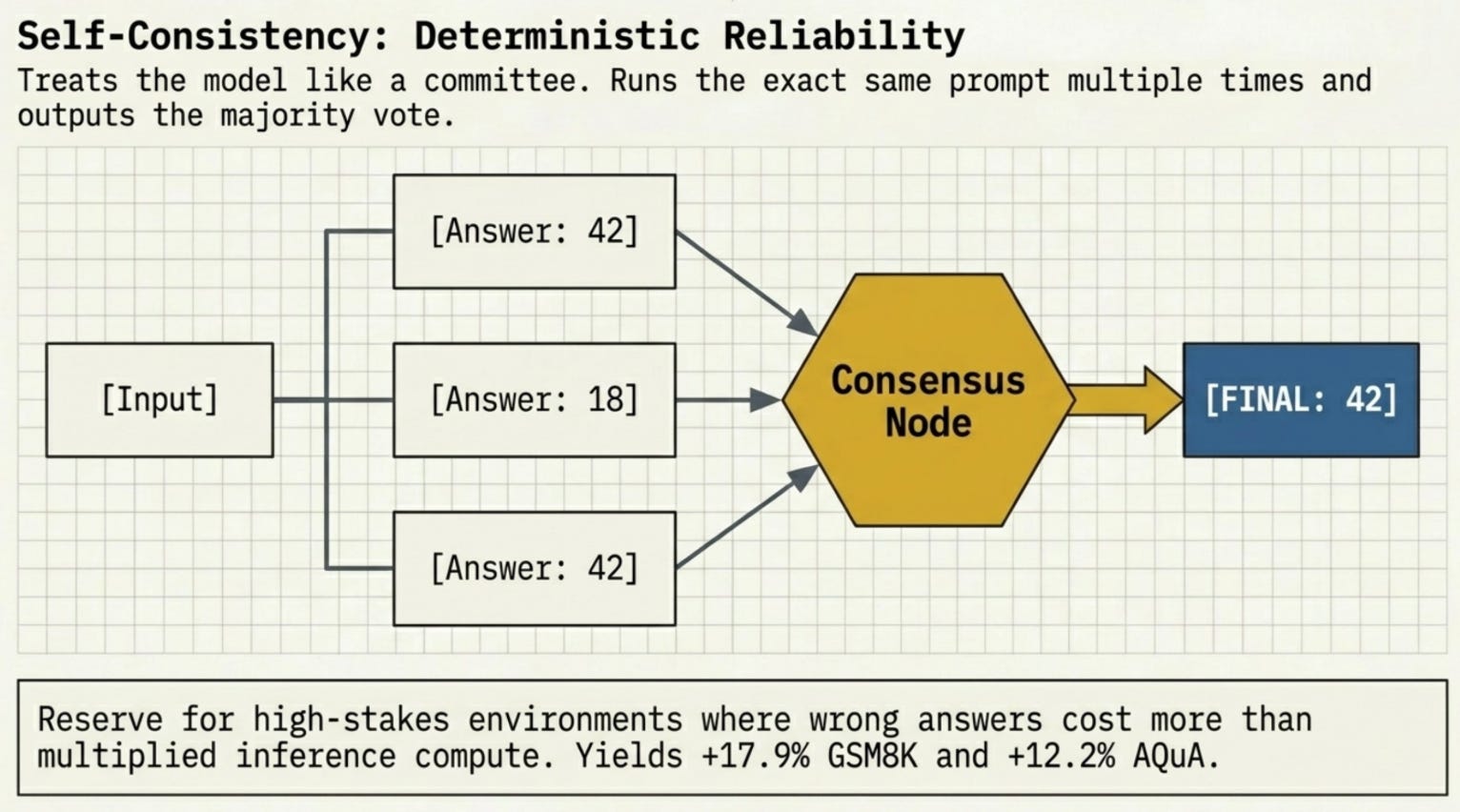
5. Self-Consistency
Self-Consistency runs the same CoT prompt multiple times, then takes the majority answer across runs (Wang et al., 2022). It treats the model like a committee: diverse reasoning paths, single most-agreed-upon answer.
Improvements over standard CoT: +17.9% on GSM8K, +11.0% on SVAMP, +12.2% on AQuA (Wang et al., 2022).
Best for: High-stakes answers where accuracy matters more than cost or speed. Avoid when: Budget is constrained -- each additional run multiplies inference cost.
Prompting Patterns: Accuracy Gain vs Compute Cost
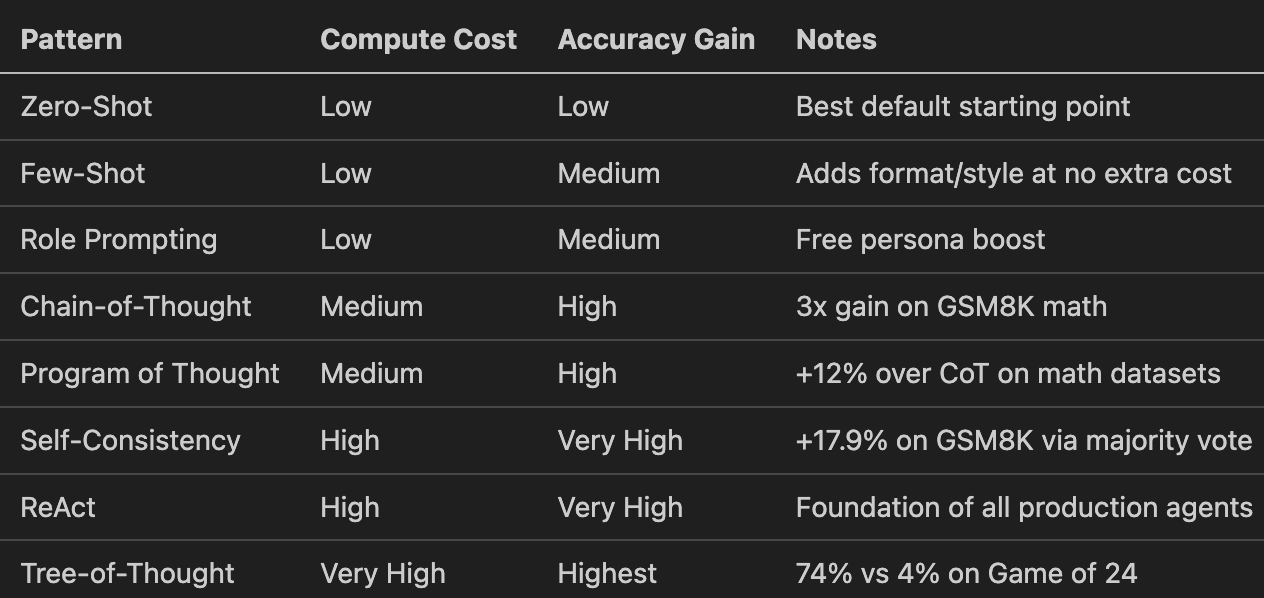
Reserve high-cost patterns for tasks where wrong answers are expensive. Start cheap and escalate.
Layer 3 -- Agentic Patterns: ReAct and Least-to-Most
6. ReAct (Reason + Act)
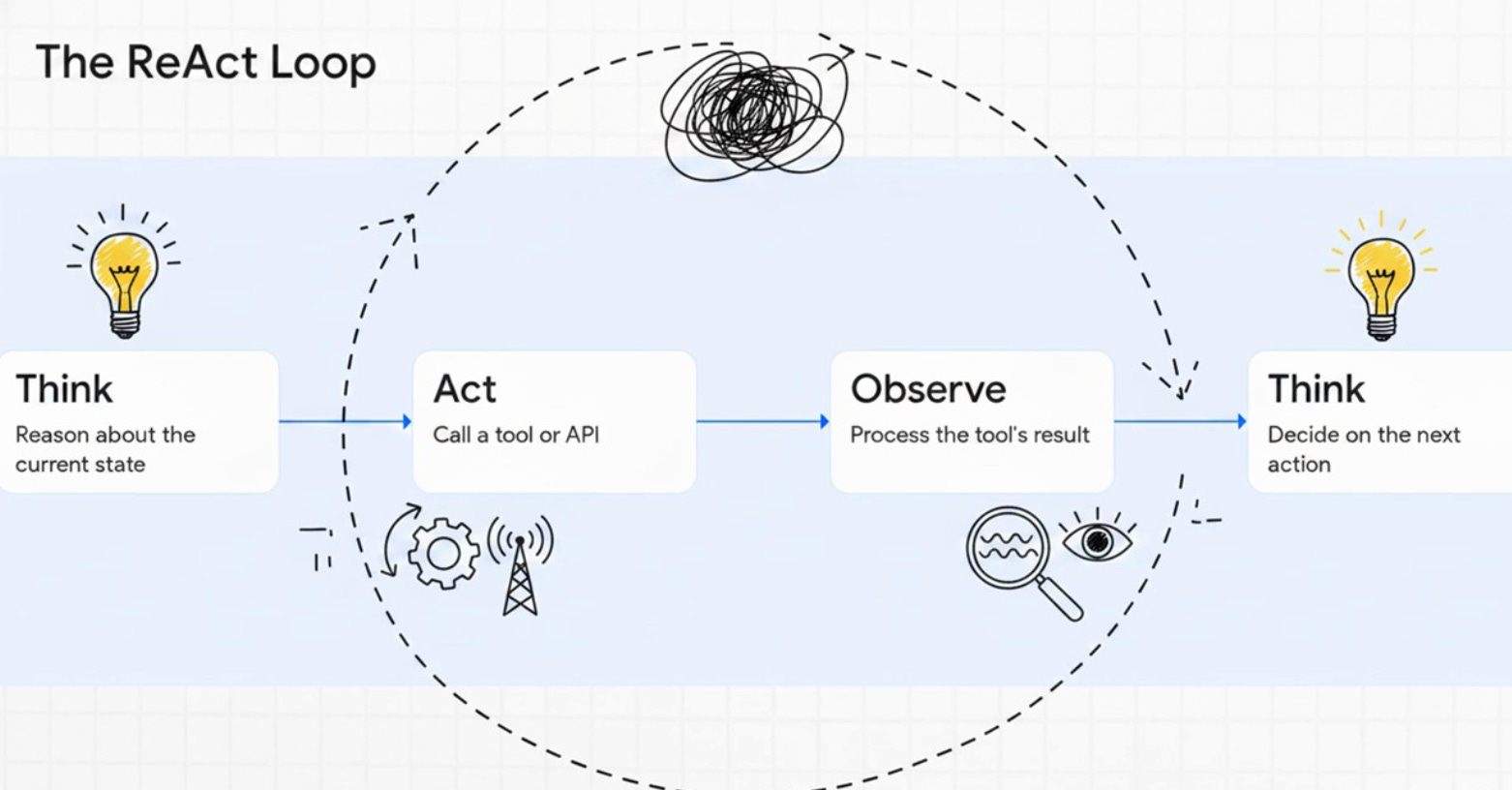
ReAct interleaves reasoning traces with actions, creating a Think -> Act -> Observe -> Think loop (Yao et al., ICLR 2023). The model doesn’t just generate text -- it decides what tool to call, observes the result, and reasons about what to do next.
Thought: I need to find the current stock price of NVDA.
Action: search("NVDA current stock price")
Observation: NVDA is trading at $875.20 as of April 7, 2026.
Thought: Now I can answer the question.
Answer: NVDA is currently at $875.20.
ReAct is the architectural backbone of most production AI agents today. It outperformed several state-of-the-art baselines on language and decision-making tasks (Yao et al., 2023).
Best for: Any task requiring tool use, web search, API calls, or multi-step actions. This is the foundation of: LangChain agents, OpenAI function calling, Claude tool use.
7. Least-to-Most Prompting
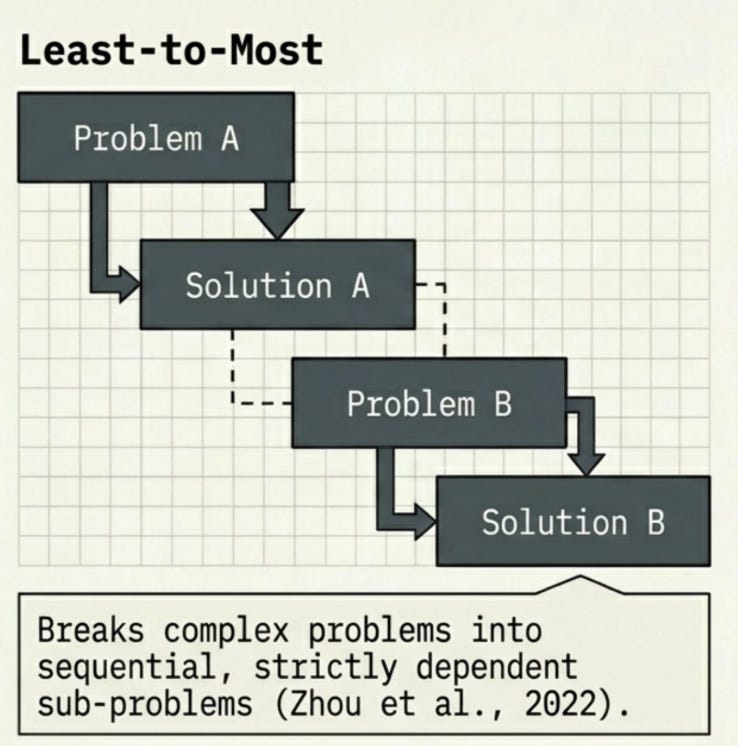
Least-to-Most breaks complex problems into ordered sub-problems and solves them sequentially, using each solution to inform the next (Zhou et al., 2022).
Step 1: What is the tax rate for this income bracket?
Step 2: Using that rate, calculate the tax owed.
Step 3: Using the tax owed, calculate the take-home pay.
Best for: Multi-step problems where steps are strictly dependent on each other.
Layer 4 -- Specialized Patterns
8. Role Prompting

Assign a persona before the task to shape tone, vocabulary, and reasoning depth.
You are a senior Python engineer with 15 years of experience reviewing code for production safety.
It’s the cheapest, simplest lever for controlling response style. A medical role prompt makes the model cite cautiously; an engineer role makes it flag edge cases.
Best for: Domain expertise simulation, consistent voice, audience-appropriate explanations.
9. Program of Thought (PoT)

Instead of reasoning in prose, PoT asks the model to write executable code to solve the problem, then runs it (Chen et al., TMLR 2023). This eliminates arithmetic errors entirely -- the computer does the math.
Write Python code to solve: "A shop sells 47 items at $8.99 each. What is total revenue?"
# Model outputs: print(47 * 8.99)
# Executed: 422.53
PoT achieved an average +12% gain over CoT across five math word problem datasets (Chen et al., 2023).
Best for: Any precise numerical calculation, data analysis, financial modeling.
10. Generated Knowledge Prompting

First ask the model to generate relevant background facts, then use those facts to answer the question. Two steps: Generate -> Reason.
Step 1: "List five key facts about how lithium-ion batteries degrade."
Step 2: "Based on those facts, explain why phone batteries lose capacity over time."
Best for: Questions requiring background knowledge the model may not immediately surface without priming.
11. Contrastive Prompting

Show both a good example AND a bad example. Teaching what to avoid is as powerful as teaching what to do.
Best for: Writing quality control, tone calibration, format enforcement.
12. Scratchpad Prompting

Give the model explicit “working space” before requiring a final answer. Like showing your work on an exam -- errors get caught mid-reasoning rather than appearing in the final output.
Best for: Complex reasoning tasks where intermediate errors cascade.
13. Directional Stimulus Prompting

Include a subtle hint or lens without constraining the full answer.
"Considering the regulatory and compliance angle, what are the risks of this architectural decision?"
Best for: Research tasks, creative work where you want a specific perspective without over-specifying.
14. Maieutic Prompting

Ask the model to explain its own reasoning recursively. Named after the Socratic method -- drawing out knowledge through questions.
"Why do you think X?"
"Now explain that reasoning further."
"What assumption does that rely on?"
Best for: Debugging model reasoning, ethics discussions, complex philosophical or causal questions.
15. Auto-CoT (Automatic Chain of Thought)
Automatically generates CoT reasoning chains from questions without manual example writing. Used in production pipelines where manual curation doesn’t scale.
Best for: Scaling CoT across large question sets without human annotation overhead.
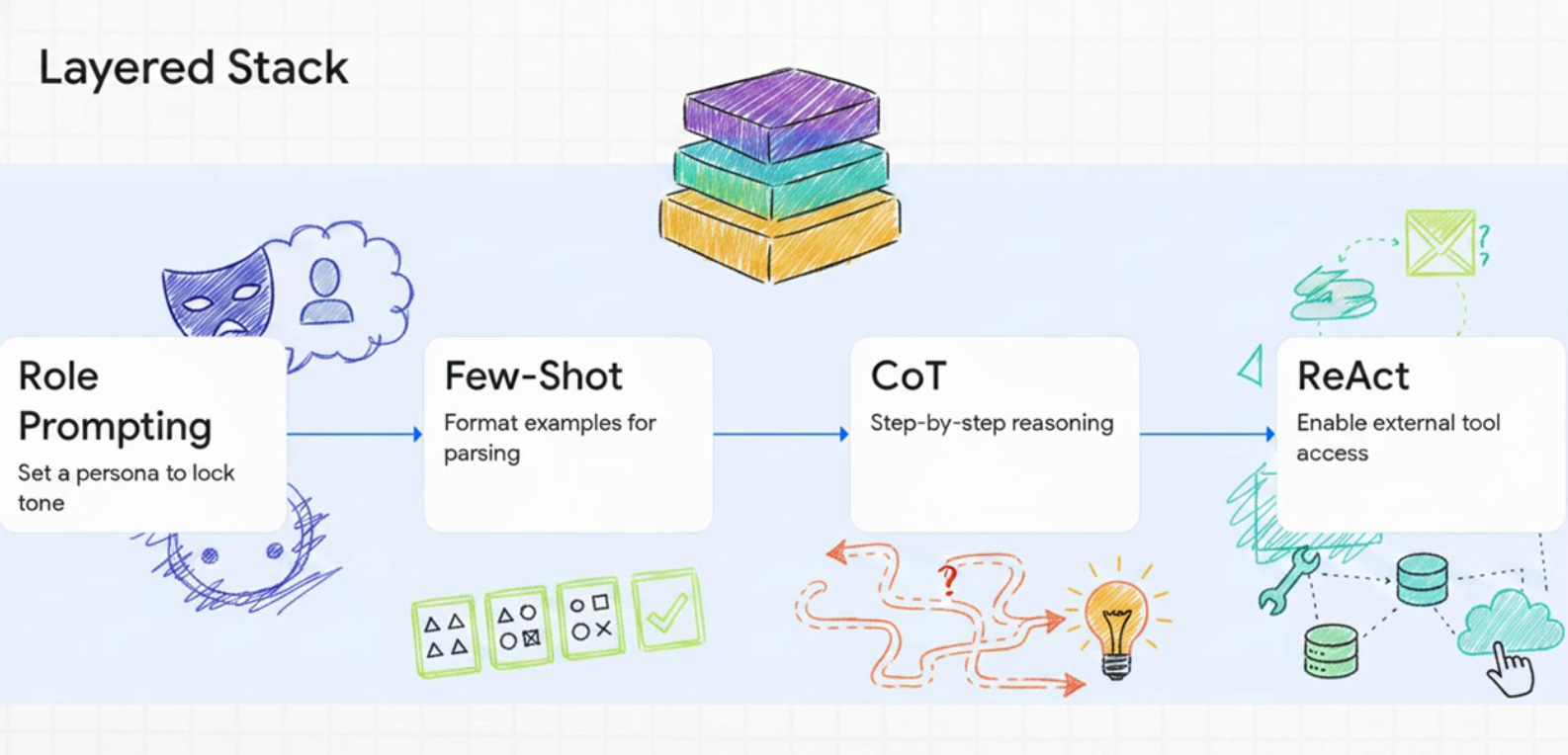
How All 15 Patterns Relate to Each Other
The patterns build in layers. Understanding this structure is more useful than memorizing individual techniques.
Simple Tasks
|
v
Zero-Shot -----> Few-Shot (add examples)
|
v
Chain-of-Thought (add reasoning steps)
|
|----> Self-Consistency (run multiple times, take majority)
|
|----> Tree-of-Thought (explore multiple branches)
|
v
ReAct (add tools + real-world actions)
|
v
AI Agents in Production
Role Prompting, Scratchpad, Generated Knowledge, Contrastive, Directional Stimulus, and Maieutic are modifiers -- they stack on top of any base pattern to tune behavior without changing the core structure.
PoT and Least-to-Most are structural alternatives -- they replace the standard reasoning format entirely when the task demands it.
The most common production pattern isn’t one technique -- it’s a layered stack: Role + Few-Shot + CoT + ReAct. Set a persona, give examples, ask for step-by-step reasoning, and enable tool calling. Each layer addresses a different failure mode.
Which Pattern Should You Use? A Decision Guide
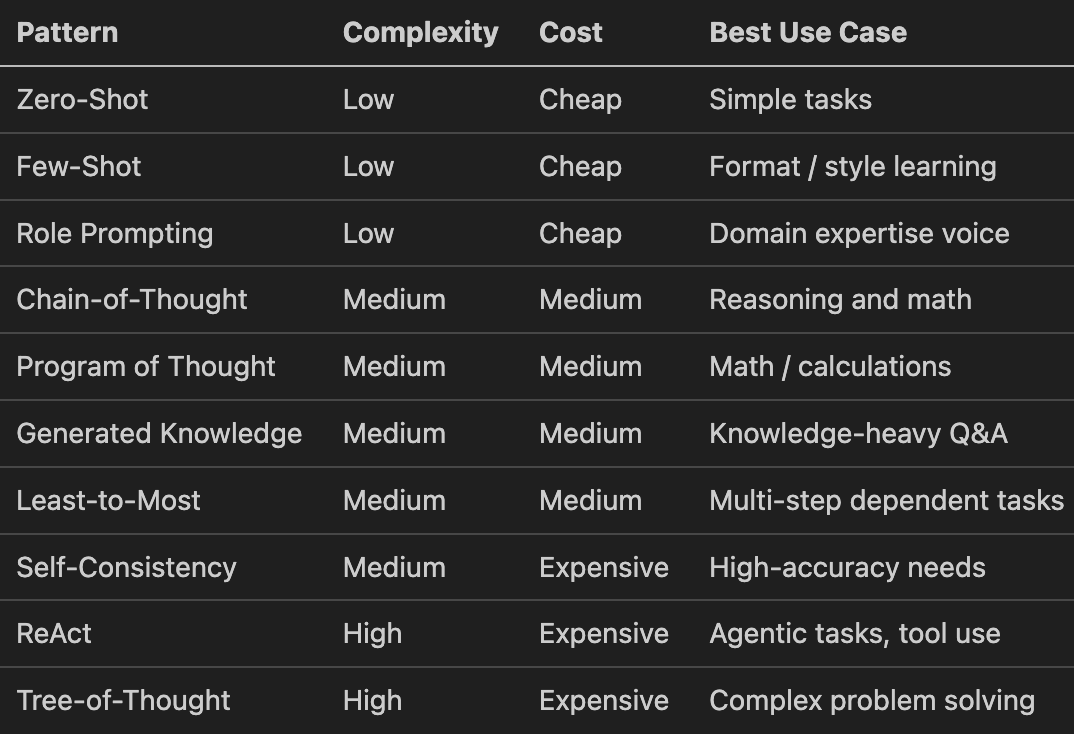
Based on research benchmarks: Wei 2022, Yao 2023, Wang 2022, Chen 2022
Frequently Asked Questions
What is the most important prompt engineering pattern to learn first?
Chain-of-Thought is the highest-leverage single technique to learn. It improved GSM8K math accuracy from 17.9% to 57.1% with no model changes (Wei et al., 2022). Adding “Let’s think step by step” to any complex reasoning task is the fastest single improvement most developers can make.
When should I use Tree-of-Thought instead of Chain-of-Thought?
Use Tree-of-Thought when your problem has multiple valid solution paths and CoT keeps failing. The key signal is backtracking -- if the correct answer requires exploring and abandoning dead ends, ToT handles this where CoT can’t. The tradeoff: ToT solved 74% of Game of 24 vs CoT’s 4%, but costs substantially more per query (Yao et al., 2023).
Is ReAct the same as an AI agent?
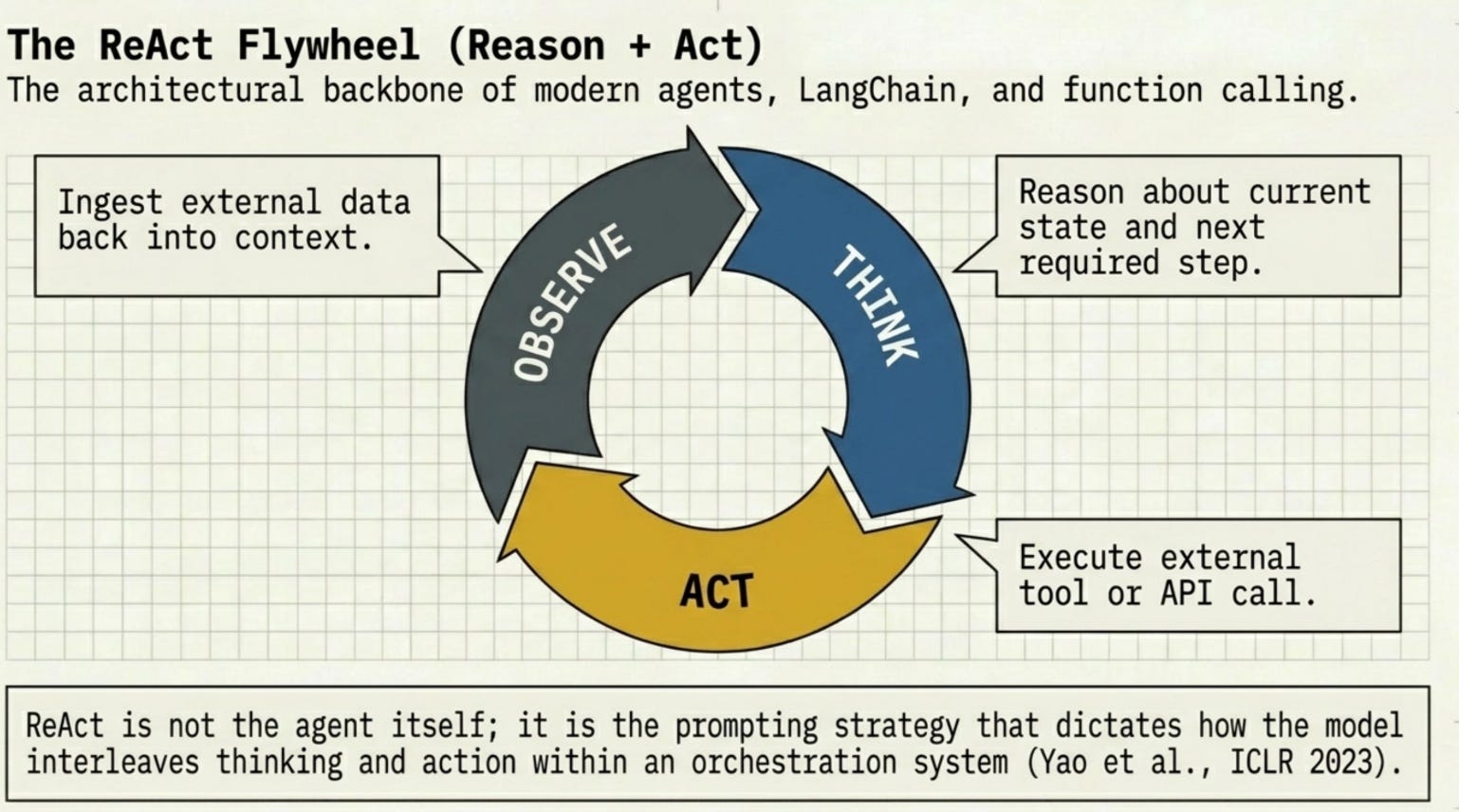
ReAct is the reasoning pattern that underlies most AI agents, but it’s not the agent itself. An agent is a system -- it has memory, tools, and orchestration logic. ReAct is the prompting strategy that tells the model how to interleave thinking and action within that system (Yao et al., ICLR 2023).
Can I combine multiple prompting patterns?
Yes -- and you should. The most effective production pipelines stack patterns. A common combination: Role Prompting (persona) + Few-Shot (format examples) + Chain-of-Thought (reasoning) + ReAct (tool access). Each layer solves a different failure mode without conflicting with the others.
What is Self-Consistency and when does its cost justify the benefit?
Self-Consistency runs the same CoT prompt multiple times and picks the majority answer. It added +17.9% on GSM8K and +12.2% on AQuA (Wang et al., 2022). The cost is justified when a wrong answer is significantly more expensive than extra inference calls -- medical diagnosis support, financial calculations, legal document analysis. For general content generation, it’s overkill.
Conclusion
The 15 patterns in this guide aren’t competing options -- they’re a toolkit. Zero-Shot is your default. Few-Shot adds format. Chain-of-Thought adds reasoning. Self-Consistency and Tree-of-Thought push accuracy at higher cost. ReAct connects the model to the real world.
The research is clear on the gains available: 3x accuracy on math reasoning, 74% vs 4% on complex problem solving, +17.9% from majority voting. These aren’t marginal improvements -- they’re architectural choices that determine whether your AI application works or doesn’t.
Start simple. Add complexity only when simpler patterns fail. Stack patterns when a single one isn’t enough.
References
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models -- Wei et al., 2022 (arXiv)
Language Models are Few-Shot Learners (GPT-3) -- Brown et al., 2020 (arXiv)
Tree of Thoughts: Deliberate Problem Solving with LLMs -- Yao et al., NeurIPS 2023 (arXiv)
Self-Consistency Improves Chain of Thought Reasoning -- Wang et al., 2022 (arXiv)
ReAct: Synergizing Reasoning and Acting in Language Models -- Yao et al., ICLR 2023 (arXiv)
Program of Thoughts Prompting -- Chen et al., TMLR 2023 (arXiv)
Least-to-Most Prompting Enables Complex Reasoning -- Zhou et al., 2022 (arXiv)
Useful roundup, and the 2026 framing is right — prompt engineering has stopped being a party trick and started being an actual skill. The bit most of these resources skip is what happens after the prompt.
I run an AI assistant across three businesses every day, and the prompt itself is maybe a fifth of the work. The other four fifths is verification: tool calls before responses, approval queues, a human sign-off before anything goes out. A clever prompt with no checks around it produces confident nonsense, and confident nonsense at scale is worse than no automation at all.
So a suggestion for the next edition: split the list in two. One half for crafting the instruction, one half for constraining the output. The second half is where the reliability lives, and it's the part nobody bookmarks because it's less fun than collecting clever system prompts.
Get the constraints right and a mediocre prompt still ships safely. Get the prompt perfect with no guardrails and you'll spend your week cleaning up after it.