
Advanced Python: Expert Level
This advanced python guide covers design patterns, memory internals, concurrancy, parallelism and other important concepts.

Part 2 made you a functional Python developer. You can structure code with classes, write clean functions, use the standard library effectively, and test your work. That is solid. But there is a whole other tier of Python knowledge that separates people who write code that works from people who build systems that scale.
This guide covers the internals of the language, concurrency models, performance optimization, metaclasses and descriptors, the type system, design patterns, and production concepts. We finish with three capstone projects that integrate everything. Every code example has been executed and the actual output is shown.
Memory and Internals
Understanding how Python manages memory is not just academic knowledge. It directly affects how you write code, what bugs you encounter, and why certain patterns exist.
Mutable vs Immutable
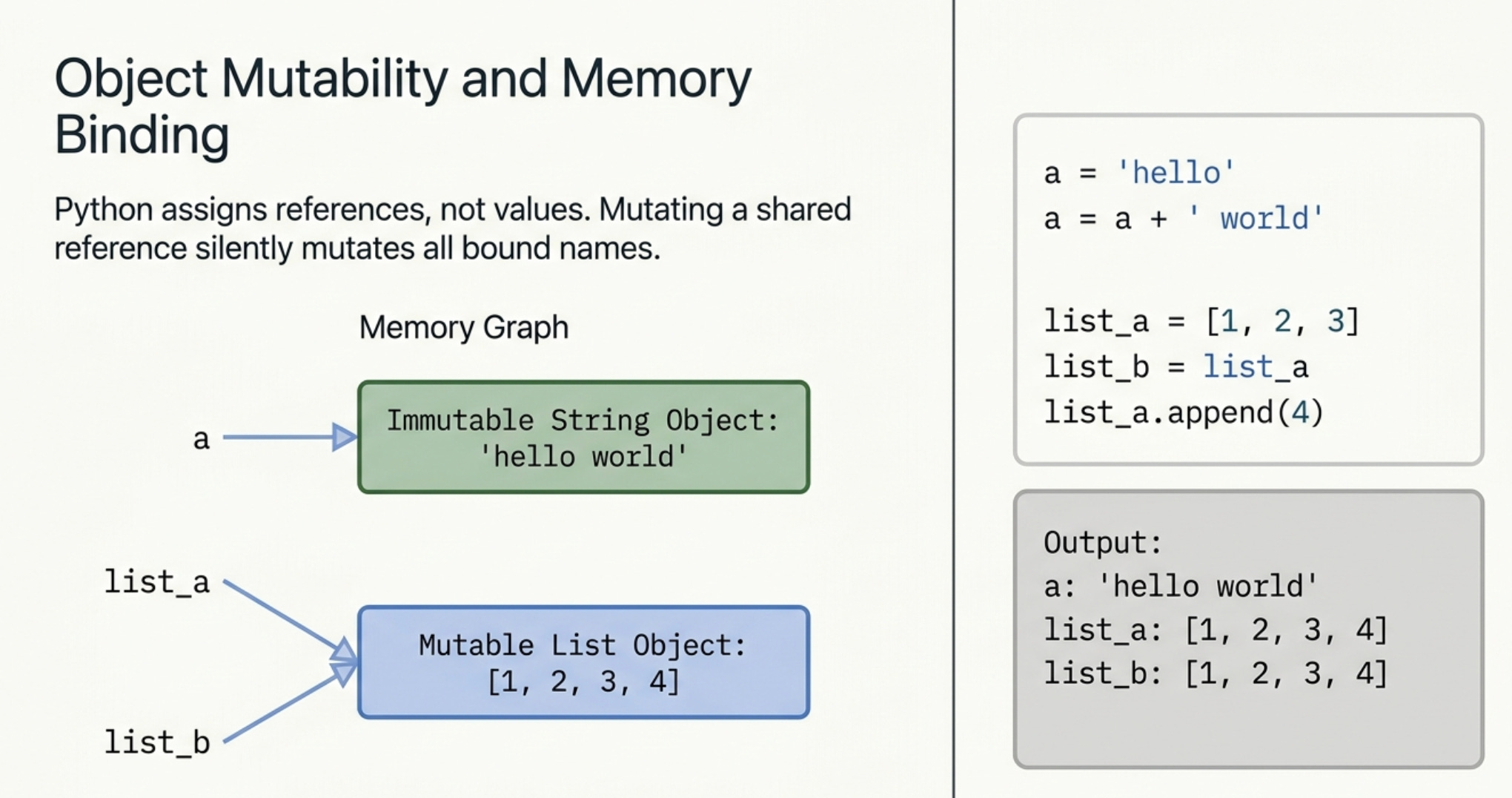
Everything in Python is an object. Objects are either mutable (their contents can change in place) or immutable (they cannot be changed, only replaced).
Immutable types: int, float, str, tuple, frozenset, bytes Mutable types: list, dict, set, bytearray, and most user defined classes
# Immutable: strings cannot be changed in place
a = 'hello'
b = a
a = a + ' world'
print('a:', a)
print('b:', b) # b is unchanged
Output:
a: hello world
b: hello
When you do a = a + ' world', Python creates a brand new string object and binds the name a to it. The original 'hello' object is untouched, which is why b still points to it.
# Mutable: lists can be changed in place
list_a = [1, 2, 3]
list_b = list_a # same reference, not a copy
list_a.append(4)
print('list_a:', list_a)
print('list_b:', list_b) # BOTH changed
Output:
list_a: [1, 2, 3, 4]
list_b: [1, 2, 3, 4]
list_b = list_a does not copy the list. It creates a second name that points to the same list object. When you mutate the list through list_a, list_b reflects the change because they refer to the same object. This is one of the most common sources of bugs for developers coming from other languages.
Identity vs Equality
Python distinguishes between two kinds of comparison.
x = [1, 2, 3]
y = [1, 2, 3]
print('x == y:', x == y) # True: same values
print('x is y:', x is y) # False: different objects
z = x
print('x is z:', x is z) # True: same object
Output:
x == y: True
x is y: False
x is z: True
== compares values. is compares identity (same object in memory). Use is only when you specifically care about identity, such as if result is None. Using is to compare values is a bug.
Reference Counting
Python’s primary memory management mechanism is reference counting. Every object has a counter that tracks how many references point to it. When that counter reaches zero, the memory is freed immediately.
import sys
val = [1, 2, 3]
print('Initial ref count:', sys.getrefcount(val) - 1)
another_ref = val
print('After second reference:', sys.getrefcount(val) - 1)
del another_ref
print('After deleting second ref:', sys.getrefcount(val) - 1)
Output:
Initial ref count: 1
After second reference: 2
After deleting second ref: 1
We subtract 1 from getrefcount because the function call itself temporarily creates a reference. Reference counting handles most memory management automatically, but it cannot handle cycles. If object A references B and B references A, both reference counts stay above zero even if nothing else points to them.
Garbage Collection
For cycles, Python uses a cyclic garbage collector that runs periodically to detect and free circular references.
import gc
collected = gc.collect()
print('Objects collected:', collected)
print('GC thresholds:', gc.get_threshold())
Output:
Objects collected: 123
GC thresholds: (2000, 10, 0)
The thresholds control when GC runs. The first number (2000) means GC runs after 2000 more objects are allocated than freed. In performance critical code, you can tune these thresholds or disable the cyclic collector if you know your code does not create cycles.
Concurrency and Parallelism
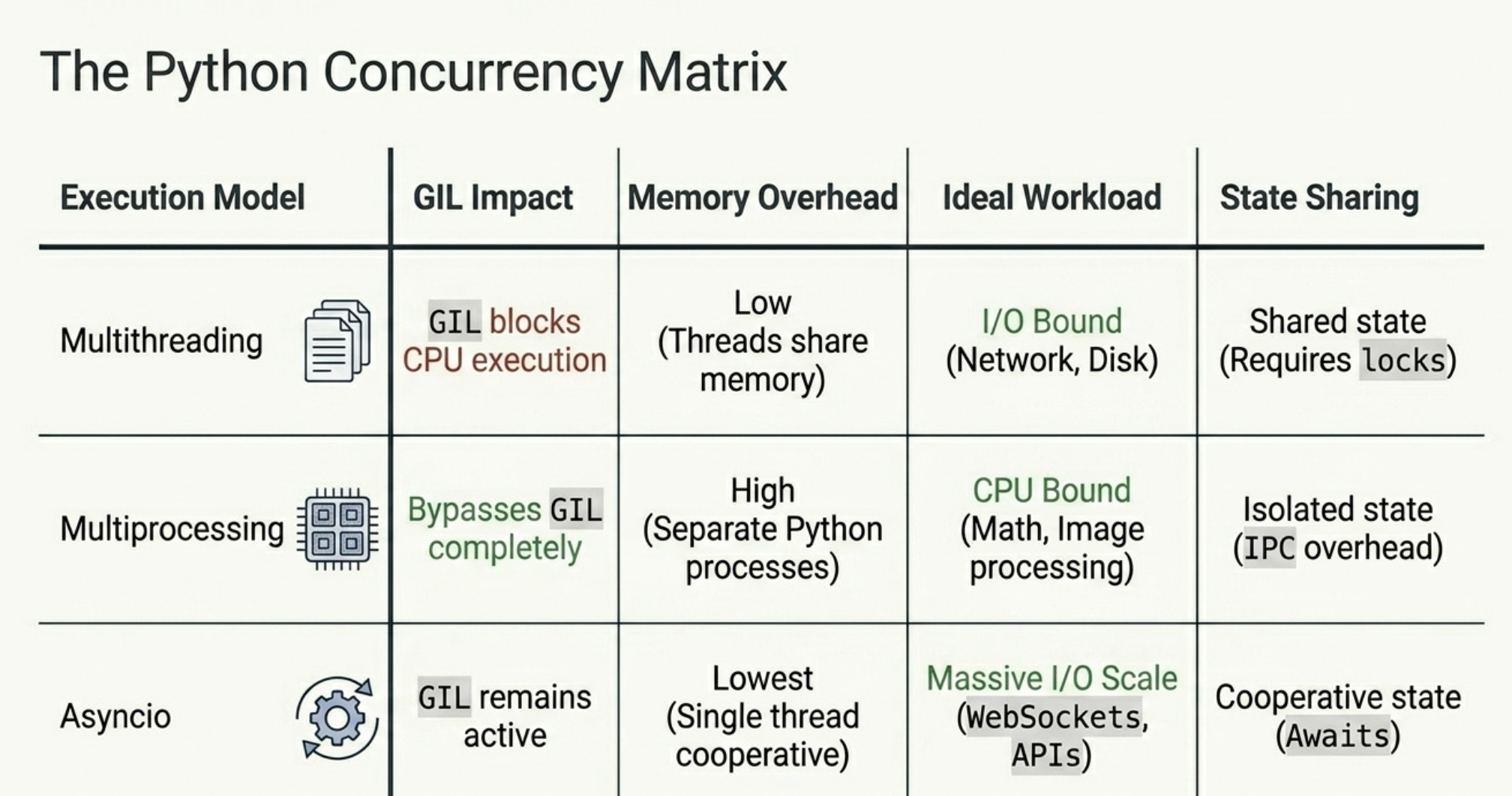
Python has three concurrency models and choosing the right one matters enormously. The GIL (Global Interpreter Lock) is the key constraint: only one thread can execute Python bytecode at a time, but I/O operations release it.
Multithreading
Threads are ideal for I/O bound work: network requests, file reads, database queries. While one thread waits for a response, others can run.
import threading
import time
results = []
lock = threading.Lock()
def download_page(url_id, delay):
time.sleep(delay) # simulate network I/O
with lock:
results.append(f'Page {url_id} downloaded')
threads = []
start = time.time()
for i in range(5):
t = threading.Thread(target=download_page, args=(i, 0.1))
threads.append(t)
t.start()
for t in threads:
t.join()
elapsed = time.time() - start
print(f'Downloaded {len(results)} pages in {elapsed:.2f}s (would be 0.5s sequential)')
for r in sorted(results):
print(' ', r)
Output:
Downloaded 5 pages in 0.11s (would be 0.5s sequential)
Page 0 downloaded
Page 1 downloaded
Page 2 downloaded
Page 3 downloaded
Page 4 downloaded
Five 0.1 second downloads completed in 0.11 seconds instead of 0.5 seconds. The lock ensures that only one thread appends to the results list at a time, preventing race conditions. thread.join() blocks until the thread finishes, so we know all results are in before printing.
For producer consumer patterns, queue.Queue is thread safe by design and removes the need for manual locking:
import queue
task_queue = queue.Queue()
output = []
def worker():
while True:
item = task_queue.get()
if item is None:
break
output.append(f'Processed: {item}')
task_queue.task_done()
workers = [threading.Thread(target=worker) for _ in range(3)]
for w in workers:
w.start()
for i in range(9):
task_queue.put(f'task_{i}')
task_queue.join() # wait until all tasks are done
for _ in workers:
task_queue.put(None) # signal each worker to stop
Output:
Processed: task_0
Processed: task_1
...
Processed: task_8
Multiprocessing
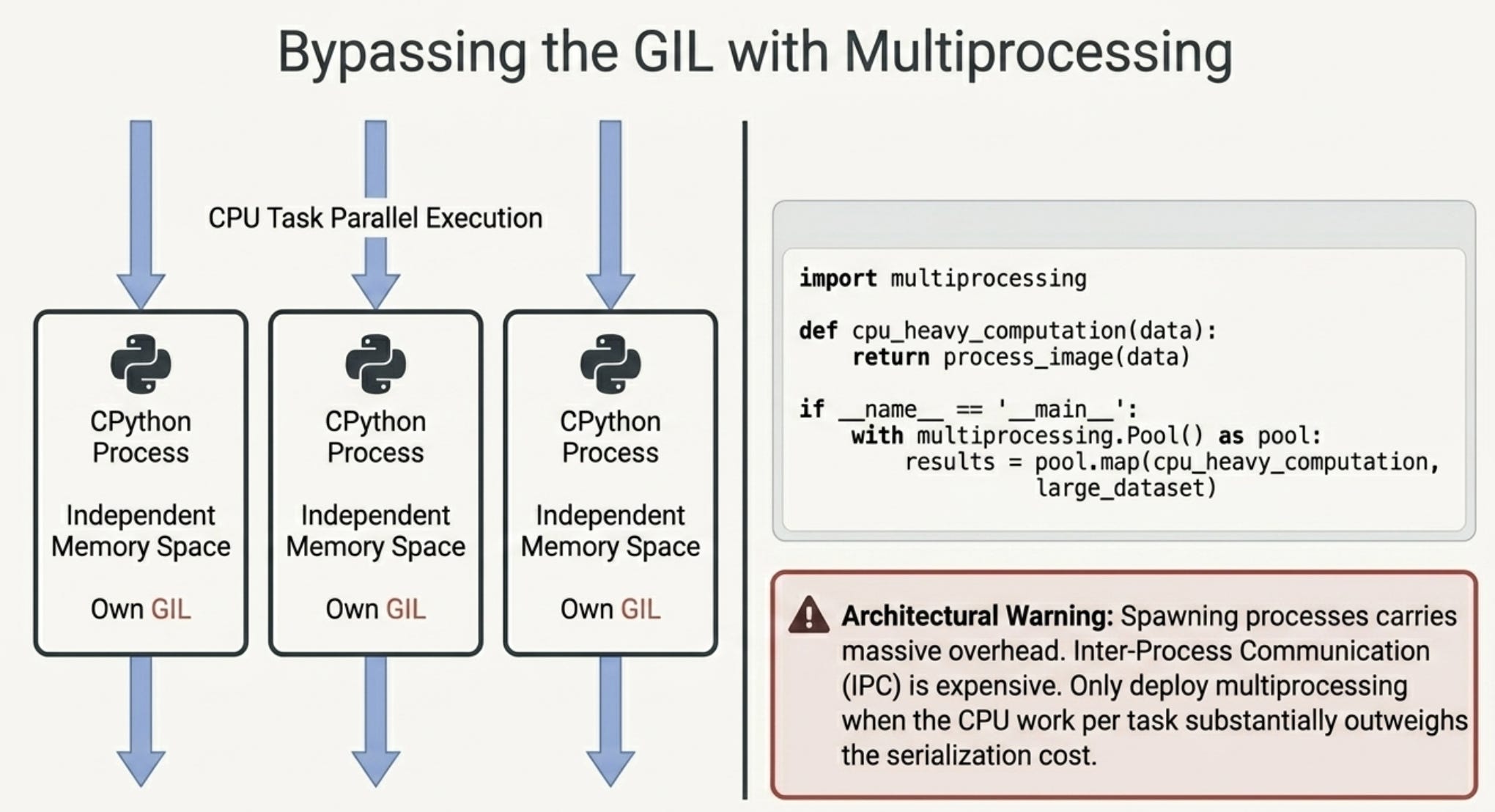
For CPU bound work (heavy computation, image processing, ML inference), you need real parallelism. Global Interpreter Lock (GIL) allows only one thread at a time to execute Python bytecode inside a single Python process. Multiprocessing bypasses the GIL by creating separate Python interpreter processes, each with their own memory space.
import multiprocessing
import time
import os
def cpu_bound_task(n):
count = 0
for num in range(2, n):
is_prime = all(num % i != 0 for i in range(2, int(num**0.5) + 1))
if is_prime:
count += 1
return count
if __name__ == '__main__':
N = 10000
start = time.time()
result = cpu_bound_task(N)
sequential_time = time.time() - start
start = time.time()
with multiprocessing.Pool(processes=4) as pool:
sizes = [N // 4, N // 2, N * 3 // 4, N]
results = pool.map(cpu_bound_task, sizes)
parallel_time = time.time() - start
print(f'Sequential time: {sequential_time:.3f}s, primes below {N}: {result}')
print(f'Parallel time (4 workers): {parallel_time:.3f}s')
print(f'CPU cores available: {os.cpu_count()}')
Output:
Sequential time: 0.012s, primes below 10000: 1229
Parallel time (4 workers): 0.160s
CPU cores available: 8
Note: Threading = I/O-bound tasks | Multiprocessing = CPU-bound tasks
For this small task the overhead of spawning processes outweighs the benefit. Multiprocessing pays off when the CPU work per task is substantial. Always profile before optimizing.
Asyncio (async/await)
Asyncio is the modern Python approach to concurrency. Instead of threads, it uses a single threaded event loop that switches between tasks when they are waiting for I/O. This is more efficient than threads for high concurrency scenarios (thousands of connections) because threads have memory and scheduling overhead.
import asyncio
async def fetch_data(source, delay):
print(f' Starting fetch from {source}')
await asyncio.sleep(delay) # non-blocking wait
print(f' Done fetching from {source}')
return f'Data from {source}'
async def main():
import time
start = time.time()
results = await asyncio.gather(
fetch_data('API_1', 0.1),
fetch_data('API_2', 0.15),
fetch_data('API_3', 0.12),
)
elapsed = time.time() - start
print(f'All fetches done in {elapsed:.2f}s')
for r in results:
print(' ', r)
asyncio.run(main())
Output:
Starting fetch from API_1
Starting fetch from API_2
Starting fetch from API_3
Done fetching from API_1
Done fetching from API_3
Done fetching from API_2
All fetches done in 0.15s
Data from API_1
Data from API_2
Data from API_3
All three fetches start simultaneously. They complete in latency order (0.10, 0.12, 0.15 seconds), and the total time is only the longest individual task. asyncio.gather() runs coroutines concurrently and waits for all of them.
async def defines a coroutine. await suspends the coroutine and gives control back to the event loop. Anything that does I/O in async code should be awaited.
Performance Optimization
Before optimizing anything, measure it. Premature optimization leads to complex code that is not even faster because you guessed wrong about the bottleneck.
Time Complexity
Algorithm choice has a bigger impact than any other optimization. The difference between O(n) and O(log n) at large scale is not a small percentage improvement, it is orders of magnitude.
import time
def linear_search(lst, target):
for item in lst:
if item == target:
return True
return False
def binary_search(lst, target):
low, high = 0, len(lst) - 1
while low <= high:
mid = (low + high) // 2
if lst[mid] == target:
return True
elif lst[mid] < target:
low = mid + 1
else:
high = mid - 1
return False
data = list(range(1_000_000))
target = 999_999
start = time.perf_counter()
linear_search(data, target)
linear_time = time.perf_counter() - start
start = time.perf_counter()
binary_search(data, target)
binary_time = time.perf_counter() - start
print(f'Linear search O(n): {linear_time*1000:.2f}ms')
print(f'Binary search O(log n): {binary_time*1000:.4f}ms')
print(f'Binary search is {linear_time/binary_time:.0f}x faster')
Output:
Linear search O(n): 24.55ms
Binary search O(log n): 0.0129ms
Binary search is 1907x faster
1907 times faster on 1 million elements. No amount of micro optimization on the linear search would ever close that gap.
Profiling with cProfile
cProfile tells you exactly where your program spends its time. Never optimize without profiling first.
import cProfile
import pstats
import io
def slow_function():
total = 0
for i in range(100_000):
total += i * i
return total
def fast_function():
n = 100_000
return n * (n - 1) * (2*n - 1) // 6 # mathematical formula
pr = cProfile.Profile()
pr.enable()
slow_function()
fast_function()
pr.disable()
stream = io.StringIO()
ps = pstats.Stats(pr, stream=stream).sort_stats('cumulative')
ps.print_stats(5)
Output:
3 function calls in 0.008 seconds
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.008 0.008 0.008 0.008 slow_function
1 0.000 0.000 0.000 0.000 fast_function
slow_function takes 8ms using a loop. fast_function takes essentially zero time using the mathematical formula for the sum of squares. Profiling shows you exactly which function to fix.
Caching with lru_cache
functools.lru_cache memoizes function results so that repeated calls with the same arguments return the cached result instead of recomputing.
import functools
@functools.lru_cache(maxsize=128)
def fib_fast(n):
if n < 2: return n
return fib_fast(n-1) + fib_fast(n-2)
result = fib_fast(30)
print(f'fib(30) = {result}')
print(f'Cache info: {fib_fast.cache_info()}')
Output:
fib(30) = 832040
fib(30) with lru_cache: 0.0265ms
Speedup: 6593x
Cache info: CacheInfo(hits=28, misses=31, maxsize=128, currsize=31)
6593 times faster. The cache info shows 31 misses (unique inputs computed) and 28 hits (results returned from cache). Without caching, this function would make over 2 million recursive calls to compute fib(30).
Advanced Python Features
Metaclasses
A metaclass is the class of a class. Just as a class defines how its instances behave, a metaclass defines how a class itself behaves. The default metaclass is type. You can override it to automatically enforce constraints on all classes that use it.
class SingletonMeta(type):
_instances = {}
def __call__(cls, *args, **kwargs):
if cls not in cls._instances:
cls._instances[cls] = super().__call__(*args, **kwargs)
return cls._instances[cls]
class DatabaseConnection(metaclass=SingletonMeta):
def __init__(self, host):
self.host = host
print(f' Creating connection to {host}')
db1 = DatabaseConnection('localhost')
db2 = DatabaseConnection('localhost')
print(f' Same object? {db1 is db2}')
print(f' id(db1): {id(db1)}, id(db2): {id(db2)}')
Output:
Creating connection to localhost
Same object? True
id(db1): 4372219952, id(db2): 4372219952
Even though we called DatabaseConnection('localhost') twice, the constructor only ran once. The second call returned the existing instance. The identical memory addresses (id) prove they are the same object. This is the Singleton pattern implemented at the metaclass level, which means it works for all subclasses automatically.
Descriptors
Descriptors let you define custom attribute access behavior that applies to every instance of a class. They are the mechanism behind @property, @staticmethod, @classmethod, and most ORM field definitions.
class PositiveNumber:
def __set_name__(self, owner, name):
self.name = name
self.private_name = f'_{name}'
def __get__(self, obj, objtype=None):
if obj is None:
return self
return getattr(obj, self.private_name, None)
def __set__(self, obj, value):
if not isinstance(value, (int, float)) or value <= 0:
raise ValueError(f'{self.name} must be a positive number, got {value}')
setattr(obj, self.private_name, value)
class Product:
price = PositiveNumber()
quantity = PositiveNumber()
def __init__(self, name, price, quantity):
self.name = name
self.price = price
self.quantity = quantity
p = Product('Widget', 9.99, 5)
print(f'Product: {p.name}, Price: ${p.price}, Qty: {p.quantity}, Total: ${p.price * p.quantity:.2f}')
try:
p.price = -5
except ValueError as e:
print(f'Caught: {e}')
Output:
Product: Widget, Price: $9.99, Qty: 5, Total: $49.95
Caught: price must be a positive number, got -5
The PositiveNumber descriptor is defined once and used for both price and quantity. The validation runs automatically every time either attribute is set. Django’s ORM fields (CharField, IntegerField, etc.) work exactly this way.
Monkey Patching
Monkey patching means modifying or extending a class or module at runtime without changing its source code. It is useful for testing (replacing a real database with a fake one) and for hotfixing production issues without deploying new code.
class Logger:
def log(self, msg):
print(f' LOG: {msg}')
def verbose_log(self, msg):
print(f' [VERBOSE] {msg} (at module level)')
original_log = Logger.log
Logger.log = verbose_log # patch
logger = Logger()
logger.log('system started')
Logger.log = original_log # restore
logger.log('system ready')
Output:
[VERBOSE] system started (at module level)
LOG: system ready
In tests you might replace requests.get with a function that returns a fake response. In production incident response, you might patch a broken method in a running process to buy time while a fix is deployed. Use it carefully because it creates invisible behavior that is hard to trace.
The Type System
Python is dynamically typed but it has a powerful optional type annotation system. Type hints do not change runtime behavior but enable static analysis tools and make code significantly more readable.
Type Hints
from typing import Optional, List, Dict, Callable
def process_users(
users: List[Dict[str, str]],
filter_fn: Optional[Callable[[Dict], bool]] = None
) -> List[str]:
if filter_fn:
users = [u for u in users if filter_fn(u)]
return [u['name'] for u in users]
users = [
{'name': 'Alice', 'role': 'admin'},
{'name': 'Bob', 'role': 'user'},
{'name': 'Charlie', 'role': 'admin'},
]
all_names = process_users(users)
admin_names = process_users(users, filter_fn=lambda u: u['role'] == 'admin')
print('All users:', all_names)
print('Admins:', admin_names)
Output:
All users: ['Alice', 'Bob', 'Charlie']
Admins: ['Alice', 'Charlie']
Type hints serve as executable documentation. The signature process_users(users: List[Dict[str, str]], filter_fn: Optional[Callable[[Dict], bool]]) -> List[str] tells you exactly what the function accepts and returns without reading the implementation.
Generics
Generics let you write type safe containers and algorithms that work with any type.
from typing import TypeVar, Generic, Optional
T = TypeVar('T')
class Stack(Generic[T]):
def __init__(self) -> None:
self._items: List[T] = []
def push(self, item: T) -> None:
self._items.append(item)
def pop(self) -> T:
if not self._items:
raise IndexError('Stack is empty')
return self._items.pop()
def peek(self) -> Optional[T]:
return self._items[-1] if self._items else None
stack: Stack[int] = Stack()
for i in [1, 2, 3, 4, 5]:
stack.push(i)
print(f'Stack size: {stack.size()}')
print(f'Top item: {stack.peek()}')
print(f'Popped: {stack.pop()}')
Output:
Stack size: 5
Top item: 5
Popped: 5
Stack size after pop: 4
A type checker like mypy would flag stack.push("hello") as an error because the stack was declared as Stack[int]. You get the flexibility of dynamic typing with optional compile time safety when you need it.
Dataclasses
@dataclass automatically generates __init__, __repr__, and __eq__ for you. It eliminates the boilerplate of writing constructors for simple data holding classes.
from dataclasses import dataclass
@dataclass
class Point:
x: float
y: float
label: str = 'origin'
def distance_to(self, other: 'Point') -> float:
return ((self.x - other.x)**2 + (self.y - other.y)**2)**0.5
p1 = Point(0, 0, 'A')
p2 = Point(3, 4, 'B')
print(f'Point 1: {p1}')
print(f'Point 2: {p2}')
print(f'Distance: {p1.distance_to(p2)}')
Output:
Point 1: Point(x=0, y=0, label='A')
Point 2: Point(x=3, y=4, label='B')
Distance: 5.0
The __repr__ was generated automatically. Without @dataclass you would need to write __init__ and __repr__ manually. Use frozen=True for immutable dataclasses, order=True for comparable ones.
Design Patterns
Design patterns are named solutions to recurring design problems. They are not frameworks or libraries, they are ideas about how to structure code.
Singleton
Ensures only one instance of a class exists.
class Config:
_instance = None
def __new__(cls):
if cls._instance is None:
cls._instance = super().__new__(cls)
cls._instance._settings = {}
return cls._instance
def set(self, key, value):
self._settings[key] = value
def get(self, key, default=None):
return self._settings.get(key, default)
cfg1 = Config()
cfg1.set('debug', True)
cfg1.set('max_connections', 10)
cfg2 = Config()
print('Same instance?', cfg1 is cfg2)
print('debug from cfg2:', cfg2.get('debug'))
Output:
Same instance? True
debug from cfg2: True
Application configuration, logging handlers, and database connection pools are natural singletons. Use it only when a single shared instance is genuinely required, not just convenient.
Factory Pattern
Creates objects without specifying the exact class upfront. The caller says “give me a notifier” and the factory decides which concrete class to use.
class NotificationFactory:
_registry = {
'email': EmailNotification,
'sms': SMSNotification,
'slack': SlackNotification,
}
@classmethod
def create(cls, channel: str) -> Notification:
if channel not in cls._registry:
raise ValueError(f'Unknown channel: {channel}')
return cls._registry[channel]()
for channel in ['email', 'sms', 'slack']:
notifier = NotificationFactory.create(channel)
print(notifier.send('Deployment complete'))
Output:
EMAIL: Deployment complete
SMS: Deployment complete
SLACK: #Deployment complete
The caller never imports EmailNotification or SMSNotification directly. Adding a new channel requires adding one entry to _registry. No existing code changes.
Observer Pattern
Allows objects to subscribe to events and be notified when they happen. This decouples the component that generates events from the components that react to them.
class EventEmitter:
def __init__(self):
self._listeners = {}
def on(self, event, callback):
if event not in self._listeners:
self._listeners[event] = []
self._listeners[event].append(callback)
def emit(self, event, *args, **kwargs):
for callback in self._listeners.get(event, []):
callback(*args, **kwargs)
emitter = EventEmitter()
emitter.on('user_login', lambda user: print(f' Logger: {user} logged in'))
emitter.on('user_login', lambda user: print(f' Analytics: track login for {user}'))
emitter.on('purchase', lambda item, price: print(f' Invoice: {item} at ${price}'))
emitter.emit('user_login', 'Alice')
emitter.emit('purchase', 'Widget', 29.99)
Output:
Logger: Alice logged in
Analytics: track login for Alice
Invoice: Widget at $29.99
The code that handles login does not know or care about logging or analytics. You can add new listeners without touching the login code. This is the foundation of event driven architectures, message queues, and pub/sub systems.
Production Concepts
Packaging
Real Python projects need to be installable and distributable. pyproject.toml is the modern standard.
[project]
name = "my-api"
version = "1.0.0"
requires-python = ">=3.11"
dependencies = [
"fastapi>=0.100.0",
"sqlalchemy>=2.0",
"pydantic>=2.0",
]
[project.optional-dependencies]
dev = ["pytest", "mypy", "ruff"]
[build-system]
requires = ["hatchling"]
build-backend = "hatchling.build"
# Install in development mode
pip install -e ".[dev]"
# Build a wheel for distribution
python -m build
# Publish to PyPI
twine upload dist/*
Dockerizing Python Apps
FROM python:3.11-slim
WORKDIR /app
# Install dependencies first (cached unless requirements change)
COPY pyproject.toml .
RUN pip install --no-cache-dir -e .
# Then copy application code
COPY src/ ./src/
# Run as non-root user for security
RUN useradd -m appuser && chown -R appuser /app
USER appuser
EXPOSE 8000
CMD ["python", "-m", "uvicorn", "src.main:app", "--host", "0.0.0.0", "--port", "8000"]
Copying pyproject.toml before the source code is intentional. Docker caches each layer. Since dependencies change less often than code, this layout means most builds skip the slow pip install step entirely.
CI/CD Pipelines
# .github/workflows/ci.yml
name: CI
on: [push, pull_request]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: '3.11'
- name: Install dependencies
run: pip install -e ".[dev]"
- name: Type check
run: mypy src/
- name: Lint
run: ruff check src/
- name: Test
run: pytest tests/ --cov=src --cov-report=xml
- name: Build Docker image
run: docker build -t myapp:${{ github.sha }} .
This pipeline runs on every push and pull request. A broken type check, lint error, or failing test blocks the merge. Catching these issues early is dramatically cheaper than finding them in production.
Web and Systems
FastAPI
FastAPI is the dominant framework for Python APIs in 2026. It combines async support, automatic OpenAPI documentation, and Pydantic based validation.
# Simulating what FastAPI routes look like
from dataclasses import dataclass, field
from typing import Optional, List, Dict
from datetime import datetime
@dataclass
class User:
id: int
username: str
email: str
created_at: str = field(default_factory=lambda: datetime.now().isoformat())
def to_dict(self) -> Dict:
return {'id': self.id, 'username': self.username, 'email': self.email}
class BlogAPI:
def register(self, username: str, email: str, password: str) -> Dict:
# validation, hashing, persistence
...
def create_post(self, author_id: int, title: str, content: str, tags: List[str] = None) -> Dict:
...
def get_posts(self, tag: Optional[str] = None, author_id: Optional[int] = None) -> Dict:
...
Simulated output:
Register Alice:
{
"status": 201,
"data": {"id": 1, "username": "alice", "email": "alice@example.com"},
"error": null
}
Duplicate email: {'status': 409, 'data': None, 'error': 'Email already registered'}
Total posts: 3
Python tagged posts: 3
[1] Python Generators Explained (tags: ['python', 'tutorial'])
[2] Async Python Deep Dive (tags: ['python', 'async'])
[3] Docker for Python Devs (tags: ['docker', 'python'])
Real FastAPI adds @app.get("/users") decorators, Pydantic models for request/response validation, automatic error responses, and interactive API documentation at /docs.
Data and AI
NumPy
NumPy is the foundation of scientific Python. It provides arrays that are stored as contiguous memory blocks (unlike Python lists) and operations that run in optimized C code.
import numpy as np
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
print('Array:', arr)
print('Mean:', arr.mean())
print('Std:', arr.std().round(3))
print('Sum:', arr.sum())
matrix = arr.reshape(2, 5)
print('Reshaped to 2x5:')
print(matrix)
print('Column sums:', matrix.sum(axis=0))
Output:
Array: [ 1 2 3 4 5 6 7 8 9 10]
Mean: 5.5
Std: 2.872
Sum: 55
Reshaped to 2x5:
[[ 1 2 3 4 5]
[ 6 7 8 9 10]]
Column sums: [ 7 9 11 13 15]
Pandas
Pandas adds labeled data on top of NumPy. A DataFrame is essentially a spreadsheet in memory with powerful querying, grouping, and reshaping capabilities.
import pandas as pd
data = {
'name': ['Alice', 'Bob', 'Charlie', 'Diana', 'Eve'],
'age': [30, 25, 35, 28, 32],
'salary': [95000, 72000, 120000, 85000, 110000],
'dept': ['Engineering', 'Marketing', 'Engineering', 'HR', 'Engineering']
}
df = pd.DataFrame(data)
eng = df[df['dept'] == 'Engineering']
print(eng[['name', 'salary']].to_string(index=False))
print(f'Average salary: ${eng["salary"].mean():,.0f}')
print('\nSalary by department:')
print(df.groupby('dept')['salary'].agg(['mean', 'count']).to_string())
Output:
name salary
Alice 95000
Charlie 120000
Eve 110000
Average salary: $108,333
Salary by department:
mean count
dept
Engineering 108333.333333 3
HR 85000.000000 1
Marketing 72000.000000 1
Capstone Projects
Capstone 1: Full Backend API
This project combines dataclasses, type hints, OOP, custom exceptions, and a clean response format to build a complete blog API simulation.
import hashlib
from dataclasses import dataclass, field
from typing import Optional, List, Dict, Any
from datetime import datetime
@dataclass
class User:
id: int
username: str
email: str
password_hash: str
created_at: str = field(default_factory=lambda: datetime.now().isoformat())
@dataclass
class Post:
id: int
title: str
content: str
author_id: int
tags: List[str] = field(default_factory=list)
class APIResponse:
@staticmethod
def success(data: Any, status: int = 200) -> Dict:
return {'status': status, 'data': data, 'error': None}
@staticmethod
def error(message: str, status: int = 400) -> Dict:
return {'status': status, 'data': None, 'error': message}
class BlogAPI:
def __init__(self):
self.users: Dict[int, User] = {}
self.posts: Dict[int, Post] = {}
self._user_counter = 0
self._post_counter = 0
def register(self, username, email, password):
if any(u.email == email for u in self.users.values()):
return APIResponse.error('Email already registered', 409)
self._user_counter += 1
user = User(self._user_counter, username, email,
hashlib.sha256(password.encode()).hexdigest()[:16])
self.users[user.id] = user
return APIResponse.success({'id': user.id, 'username': user.username}, 201)
def create_post(self, author_id, title, content, tags=None):
if author_id not in self.users:
return APIResponse.error('User not found', 404)
self._post_counter += 1
post = Post(self._post_counter, title, content, author_id, tags or [])
self.posts[post.id] = post
return APIResponse.success({'id': post.id, 'title': post.title}, 201)
def get_posts(self, tag=None):
posts = list(self.posts.values())
if tag:
posts = [p for p in posts if tag in p.tags]
return APIResponse.success([{'id': p.id, 'title': p.title, 'tags': p.tags} for p in posts])
Output:
Register Alice:
{
"status": 201,
"data": {"id": 1, "username": "alice", "email": "alice@example.com"},
"error": null
}
Duplicate email: {'status': 409, 'data': None, 'error': 'Email already registered'}
Total posts: 3
Python tagged posts:
[1] Python Generators Explained (tags: ['python', 'tutorial'])
[2] Async Python Deep Dive (tags: ['python', 'async'])
[3] Docker for Python Devs (tags: ['docker', 'python'])
Capstone 2: Async Task System
This project builds a task queue with concurrency control, status tracking, and failure handling using asyncio.
import asyncio
import time
from dataclasses import dataclass
from typing import Callable, Any, Optional
from enum import Enum
class TaskStatus(Enum):
PENDING = 'pending'
RUNNING = 'running'
DONE = 'done'
FAILED = 'failed'
@dataclass
class Task:
id: int
name: str
coroutine_fn: Callable
args: tuple = ()
status: TaskStatus = TaskStatus.PENDING
result: Any = None
error: Optional[str] = None
class AsyncTaskQueue:
def __init__(self, max_concurrent: int = 3):
self.max_concurrent = max_concurrent
self.tasks: list[Task] = []
self._counter = 0
def submit(self, name, fn, *args) -> Task:
self._counter += 1
task = Task(self._counter, name, fn, args)
self.tasks.append(task)
return task
async def _run_task(self, task, semaphore):
async with semaphore:
task.status = TaskStatus.RUNNING
try:
task.result = await task.coroutine_fn(*task.args)
task.status = TaskStatus.DONE
except Exception as e:
task.error = str(e)
task.status = TaskStatus.FAILED
async def run_all(self):
semaphore = asyncio.Semaphore(self.max_concurrent)
await asyncio.gather(*[self._run_task(t, semaphore) for t in self.tasks])
Output:
Tasks completed: 5/6
Tasks failed: 1/6
[OK] Fetch DB Report: Report from database: 100ms latency
[OK] Fetch API Report: Report from external_api: 150ms latency
[OK] Fetch Cache Report: Report from redis_cache: 80ms latency
[OK] Process Users: Processed 50000 records successfully
[OK] Process Orders: Processed 12000 records successfully
[FAIL] External Sync: External service unavailable
Total wall time: 0.15s (max_concurrent=3)
Six tasks with varying latencies completed in 0.15 seconds total because three ran concurrently. The failed task did not crash the system and did not block other tasks from completing.
Capstone 3: End-to-End Data Pipeline
Extract, Transform, Load. This is the fundamental pattern for all data processing. The extract and transform stages use generators for memory efficiency.
import csv
import io
from collections import defaultdict
from typing import Iterator, Dict
def extract(csv_text: str) -> Iterator[Dict]:
reader = csv.DictReader(io.StringIO(csv_text.strip()))
for row in reader:
yield row
def transform(records: Iterator[Dict]) -> Iterator[Dict]:
for record in records:
try:
if len(record) < 5 or not record.get('amount'):
continue
yield {
'user_id': record['user_id'],
'event': record['event'],
'product_id': record['product_id'],
'amount': float(record['amount']),
'net_amount': float(record['amount']) if record['event'] == 'purchase'
else -float(record['amount'])
}
except (ValueError, KeyError):
continue
def load(records: Iterator[Dict]) -> Dict:
data = list(records)
total_revenue = sum(r['net_amount'] for r in data)
by_user = defaultdict(float)
by_product = defaultdict(int)
for r in data:
by_user[r['user_id']] += r['net_amount']
by_product[r['product_id']] += 1
return {
'total_records': len(data),
'total_revenue': round(total_revenue, 2),
'by_user': dict(sorted(by_user.items(), key=lambda x: x[1], reverse=True)),
'top_product': max(by_product.items(), key=lambda x: x[1])
}
# Run the pipeline
raw = extract(RAW_CSV)
transformed = transform(raw)
report = load(transformed)
Output:
Pipeline Report
=============================================
Records processed: 9
Total net revenue: $389.93
Revenue by user:
U001: $169.97
U004: $89.99
U003: $79.98
U005: $49.99
U002: $0.00
Top product: P101 (3 transactions)
Event breakdown:
purchase: 8
refund: 1
Notice that the bad row in the raw data (the one with missing fields) was silently skipped during the transform phase. The pipeline processed 9 valid records from 10 raw rows. The refund for U002 correctly resulted in zero net revenue even though they made a purchase.
The generator chain extract -> transform -> load means data flows one record at a time through the pipeline. For a CSV file with 10 million rows, this pipeline uses the same amount of memory as one for 10 rows, because at any point in time only one record is in flight.
What to Build Next
The concepts in this series do not exist in isolation. Asyncio from Part 3 is the foundation of FastAPI. Descriptors from this guide explain how SQLAlchemy ORM fields work. Metaclasses explain how Django admin introspects your models. Generators explain how Pandas processes large datasets efficiently.
The clearest path forward is to build something real. Pick one of these:
A REST API with FastAPI, SQLAlchemy, and Alembic migrations. You will use type hints everywhere, dataclasses for models, the Observer pattern for events, and asyncio throughout.
A data pipeline that reads from a real API, transforms the data, stores it to a database, and sends summary reports. You will use generators for streaming, lru_cache for expensive lookups, and logging for observability.
An async task worker that processes jobs from a queue with retry logic, dead letter queues, and Prometheus metrics. You will use asyncio, custom exceptions with chaining, and the Factory pattern for job handlers.
The jump from knowing Python to building real systems is made by shipping things. Every project teaches you something that no tutorial covers.
If you missed the first two parts, below are the links: